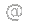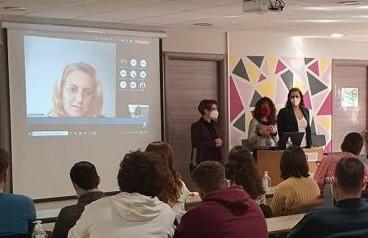



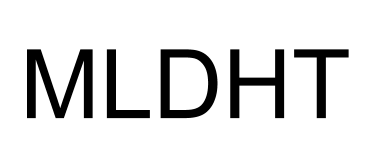





Με λένε Ιάσονα Ανδριόπουλο και υπήρξα φοιτητής του ΟΠΑ τόσο στις προπτυχιακές μου σπουδές στο τμήμα Πληροφορικής (2008) όσο και στις μεταπτυχιακές μου σπουδές στο τμήμα της Επιστήμης Υπολογιστών (2015). Έχω εργαστεί σε διάφορες εταιρείες και οργανισμούς στο τομέα της ανάπτυξης λογισμικού με πιο πρόσφατη θέση αυτή του Machine Learning Software Engineer στην Deus Ex Machina. Θεωρώ ότι οι σπουδές μου παρείχαν μια σωστή ισορροπία ανάμεσα στην πράξη και στην θεωρία η οποία μέχρι τώρα έχει αποδειχθεί εξαιρετικά χρήσιμη – Οι προγραμματιστικές εργασίες με προετοίμασαν για τα πρώτα στάδια της καριέρας μου ενώ το θεωρητικό υπόβαθρο μου επιτρέπει ως και σήμερα να εξελίσσομαι και να μαθαίνω νέες τεχνολογίες.








 Πατησίων 76
Πατησίων 76 210-8203315,316
210-8203315,316